3.3. Async
Unlike traditional software systems that operate mostly by giving you instant answers, current generative AI systems are fundamentally asynchronous.
For example, when using a language model like ChatGPT, users type their queries into a text box. This input is then sent to the back-end server for processing and streaming. Streaming enables real-time data flow between the client and server, providing users with incremental updates. For example, in a chat application, a generative AI can stream responses as they are being generated. This creates a more dynamic and engaging user experience, as users can see partial responses and start interpreting them even before the entire output is completed.
Standard UI elements like buttons and sliders are also used to trigger AI actions. These triggers can initiate complex back-end processes, such as generating an image, composing a piece of music, or performing data analysis. The asynchronous nature of these interactions allows the front-end interface to remain responsive, providing users with immediate feedback while the back-end handles the heavy lifting.
The back-end of these systems is generally where the bulk of processing occurs. For example, a user might upload a large PDF document and request a summary. The AI system will process this document asynchronously, allowing the user to continue other activities. Once the summary is ready, the system can notify the user, ensuring a seamless experience without requiring them to wait for the task to complete.
The ability to process tasks in the background offers several key benefits. One significant advantage is the control over concurrency. This is particularly important for services that rely on external APIs, especially those involving paid models. By regulating the number of requests made to these APIs, systems can optimize their usage and control costs effectively. This is more difficult on the front-end where we can't always control how often users interact with particular features.
The size of generative AI models plays a crucial role in determining their performance and accuracy. Larger models, while often more accurate and capable of generating higher-quality outputs, tend to be slower. This slowness is the trade-off for their greater accuracy and depth of understanding. On the other hand, smaller models, though less capable of nuanced and complex responses, are typically faster. This speed is particularly evident when running smaller models on hardware designed for larger ones, as the hardware's capabilities are underutilized, resulting in quicker response times.
Another permutation of this idea is edge AI. It involves deploying artificial intelligence directly onto peripheral devices, making each device a miniature decision-making hub. This contrasts with relying on the cloud for computational power. Essentially, it’s like having a small, independent brain in your smart gadgets, eliminating the need to constantly communicate with a more powerful, distant brain. That said, edge AI often lags behind its cloud-based counterpart because local devices like laptops lack the computing prowess of centralized servers. However, if you have a small model fine-tuned for a very specific, simple task that runs directly on your laptop or phone, it can deliver an answer without needing to communicate with the cloud, eliminating the time needed to handle server requests.
Case study: OpenAI o1
In September 2024, OpenAI advanced the concept of asynchronous AI with the release of the GPT-1o model. This model was built to take more time to think before responding, allowing it to reason through complex tasks and solve more challenging problems in areas like science, coding, and math. When I tested it, the model took 12 to 20 seconds to begin generating text, and then a few more seconds to complete the response once it started.
When it finished, it showed me the chain of thoughts that led to its answer.
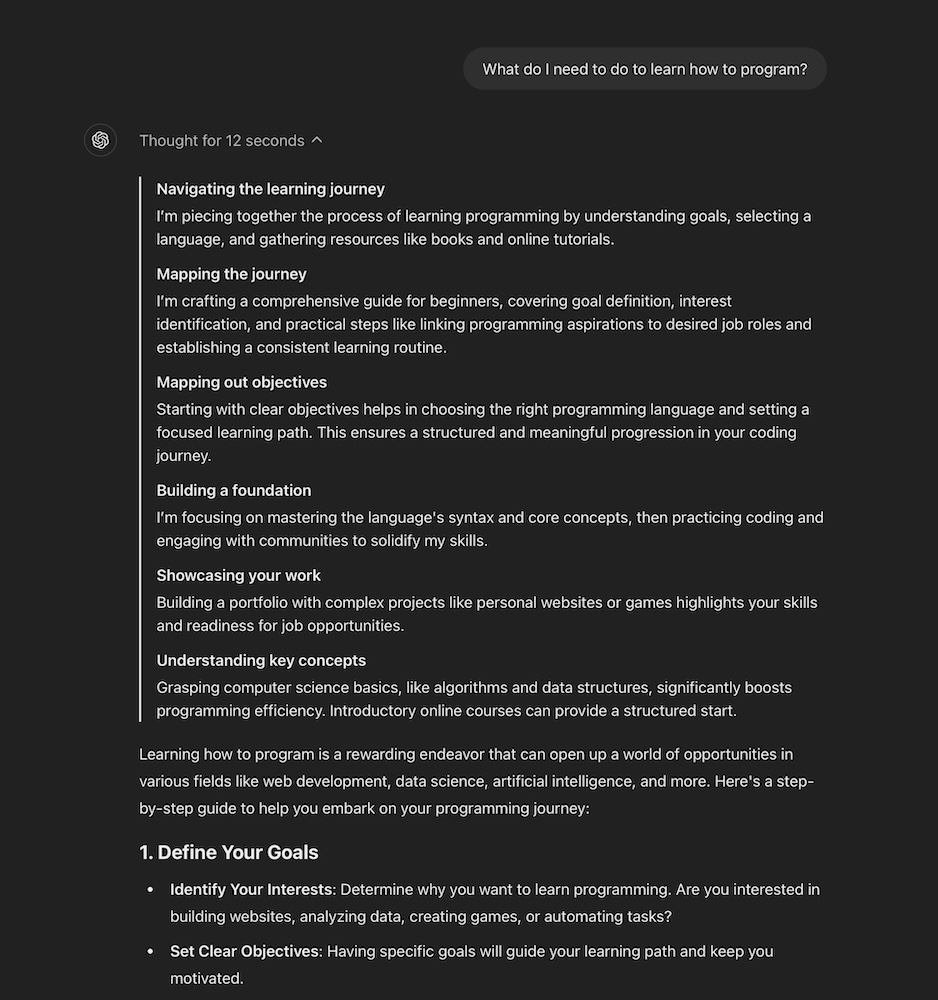
OpenAI’s o1 represents a significant shift not just in research, but also in how products are developed. We’re now faced with the challenge of building around a model that takes time to think. For the past two decades, we’ve focused on shrinking feedback loops to mere milliseconds—whether it’s media, communication, computing, or hardware. Everything became so fast that we trained people to expect immediate responses. But generative AI is changing that dynamic. OpenAI has even mentioned that future versions of o1 might think for hours, days, or even weeks! This is a radical departure from what today’s fast-paced, dopamine-driven culture is used to. However, if the end result is so valuable that it’s worth the wait, who’s to say this isn’t where software development is headed in the next decade?
Now, product designers face a whole new set of challenges with this evolving interaction model. Can we even call something that takes hours or weeks to process a chatbot anymore? Is text input still the best way for users to engage with it? Are chat bubbles the right format to display results? If tasks take that long, should there be a progress pipeline that lets users review results step by step? And what if you catch an error early in the process—can you intervene, or are you stuck waiting for the final output to correct mistakes? Any data analyst knows the frustration of waiting for a lengthy and costly query to complete, only to realize you made an error, making the results useless and forcing you to start all over. These are critical questions designers must now grapple with.
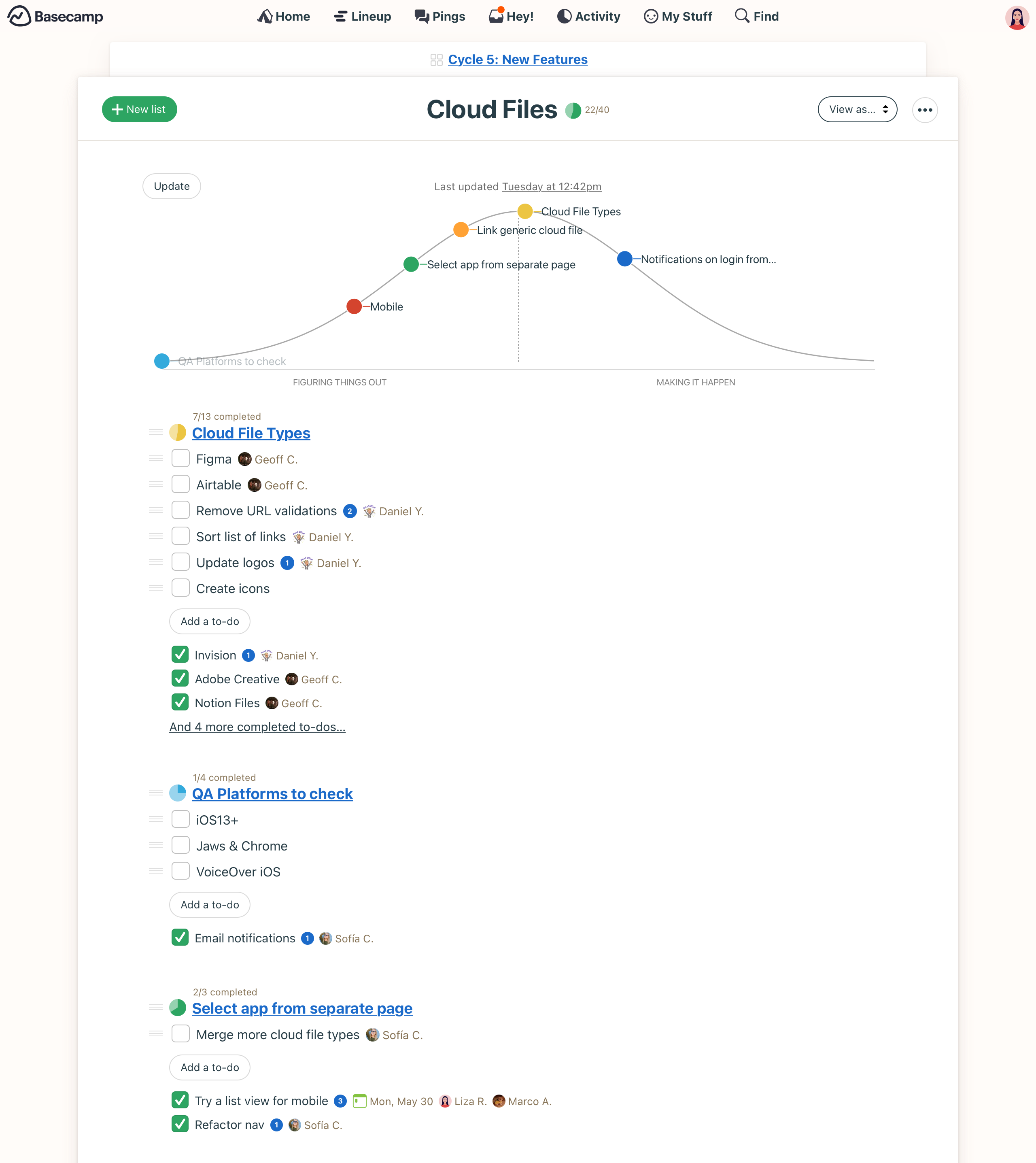
If you’re a designer working on an agentic AI app right now, you likely need to look to other fields for inspiration on addressing these challenges. My guess is that the most relevant design patterns will come from industries that manage long-running, often physical, processes. Beyond data science, you could look at areas like shipping, which developed tools like email notifications, text updates, and live maps to show users where their package is and when it will arrive. Project management tools are another great example—they allow stakeholders to easily track the progress of long-term projects. What if your AI agent used something like a hill chart to visualize its progress, giving users a clear, intuitive view of how far along it is and what’s left to be done? These industries provide valuable lessons on keeping users informed and engaged during lengthy processes.